WIN32汇编第10章 内存管理和文件操作 ・ 10.2 文件操作(1)
WIN32汇编语言教程:第10章 内存管理和文件操作 ・ 10.2 文件操作(1)
10.2.1 Windows的文件I/O
在DOS操作系统下,最早的文件操作方法是使用FCB(文件控制块),FCB是一个数据结构,为了存取一个文件,必须建立一个FCB并在其中填写好驱动器名、文件名和要读写的记录号等,然后调用int 21h中对应的功能。使用FCB方式的缺点很多,如每次只能按记录为单位读取数据,无法随意指定数据块大小,无法直接指定一个全路径的文件名,文件的操作位置不会自动调整,每次操作都必须指定记录号等,归纳起来就是功能简单,操作复杂。
于是在2.0以上的DOS版本中,开始使用更方便的文件句柄方式,这种方式不再需要文件控制块,程序指定一个包含全路径的文件名后,就可以要求操作系统打开这个文件并返回一个文件句柄,以后就可以用这个句柄来读写文件,直到关闭文件为止。操作系统在内部为每个文件句柄维护一个读写指针。读写指针总是指向文件下一次要存取的位置,每次对文件的读写操作完成以后,读写指针会自动调整到本次操作的最后一个字节后面的位置,这样顺序读写文件就不必每次重新指定位置。读写指针可以被移动到文件的任意位置,以便满足随机存取的要求。
Windows操作系统中,文件操作沿用了这种句柄方式,保留了文件句柄和读写指针等概念,同时又根据Windows操作系统的新特征对文件I/O进行了很多的扩展,下面列出了Win32中文件函数经过扩展的一些功能:
● 文件函数的操作对象有了很大的扩展,除了普通的文件,对串口、磁盘设备、网络文件、控制台和目录等的操作都可以使用文件函数来完成。
● 支持异步文件操作,文件函数可以不必等待到操作完成才能返回。
● Windows是多用户的操作系统,可能发生多个程序同时对文件操作的现象,文件函数中增强了对共享和锁定的支持。
● 文件操作函数和内存映射文件函数配合可以实现将文件当做内存的一部分来存取的功能。
● 增加了拷贝文件和移动文件等函数来实现常用的功能。
另外,在文件的命名中有长短文件名之分,众所周知,DOS操作系统使用8.3结构的文件命名方式,在这种命名方式下,用文件名来简单地说明文件的用途显得比较困难,因为仅用8个字符是表达不了什么复杂的含义的。
而在长文件名系统中,文件名的长度可以长达255个字符,这样在文件名中就可以清晰地表达出文件的用途,长文件名在磁盘的目录区中占用了多个连续的目录项,其中的一个目录项用做8.3结构的短文件名,其他的目录项存放其他名字字符。在8.3文件名中不合法的一些字符,如小数点与空格等在长文件名中都可以使用,只有/ \:*?"<>|等9个字符不能用于长文件名。
长文件名需要文件系统的支持,从DOS到Windows,使用过的有FAT,VFAT,FAT32,NTFS与HPFS等多种文件系统,在这些文件系统中,只有FAT系统不支持长文件名。
各种操作系统对文件系统的支持是不同的。Windows 3.x和DOS操作系统一直使用的是文件分配表(FAT)系统;Windows 95开始使用扩展FAT文件系统(VFAT),FAT系统和VFAT系统都是16位的文件系统,也称为FAT16。Windows NT在支持FAT16的同时,还支持两种32位的文件系统:NT文件系统(NTFS)和高性能文件系统(HPFS),NTFS支持文件的安全性,能够指定谁能访问某一文件或目录和对它做什么操作。Windows 98在支持FAT16的同时,也支持32位的FAT文件系统(FAT32),但Windows 9x系列操作系统不支持NTFS和HPFS。Windows 2000则支持上面所列的所有文件系统。
那么在Win32的文件操作函数中,如何处理长、短文件名,又如何处理不同的文件系统呢?答案很简单:就是不要去考虑它们,不管要操作的文件名是长是短,不管文件位于什么样的文件系统中,只要指定了正确的文件名,文件操作函数就能正确地处理它。
10.2.2 创建和读写文件
在开始讨论文件I/O的函数之前,先来看一个例子,这是一个对文本文件中的英文单词进行统计的小程序WordCount,程序将文本文件读入并分析文件内容,最后将统计结果保存到记录文件中,比如对包含下面文本的文件进行统计,就会得到如图10.4所示的记录文件:
“He's one of my best friend, a very very good man and has a very very good job and their relationship used to be so charming and stable, but now changed.”
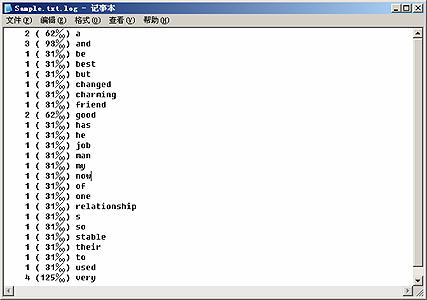
图10.4 WordCount程序的运行结果
为了实现程序的功能,除了读文本文件和写记录文件外(这部分在本节中逐步介绍),还要涉及如何设计程序的结构。虽然可以用一个比较笨的办法:首先读一个单词,将它保存在缓存区中并为它增加一个计数,以后每读到一个单词就和以前保存的所有单词比较一下,如果存在则增加计数,不存在则保存一个新单词,但这种办法随着数据的增长工作量会急剧增加,所以例子程序用了另外一种方法:就是用树型结构的办法。
如图10.5所示,树的每个结点中有个计数器,还有26个子结点指针,子结点指针根据单词中的下一个字母是A~Z分别指向不同的子结点,假如我们遇到一个单词“ver”,就为它创建4层结点,第1层结点中的第22个指针(代表V)指向第2层,第2层结点中的第5个指针(代表E)再指向第3层结点,同样第3层结点中第19个指针(代表R)指向第4层结点,并将第4层结点的计数中增加1表示遇到了一个“ver”单词。
如果遇到单词“very”,那么继续创建第5层结点,并将V->E->R结点下的第25个指针中(代表Y)指向这个第5层结点,同时将这个第5层结点的计数加1。
如果遇到一个单词“var”,那么在第2层结点中的A位置将出现一个分支指向另一个第2层结点。这样一来,数据树最大可能的深度就是单词的最大长度。
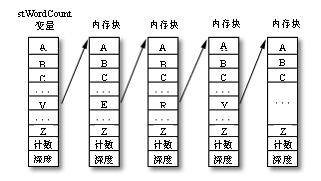
图10.5 WordCount程序中的内存结构
为结点定义了一个数据结构:
WORD_COUNT struct lpLetter dd 26 dup (?) dwCount dd ? dwDepth dd ? WORD_COUNT ends
结构中设置了26个指针用来指向下一层结点,分别代表下一个字母分别是A~Z的情况,如果没有下一个字母,则指针设置为NULL,dwCount字段用来计数。
每当程序遇到一个单词的开始字母,就从第1层结点开始处理,如果对应位置的指针已经存在,则继续移动下去,如果不存在,表示以前还没有遇到这样的单词,那么就新申请一块内存建立一个下层结点,依此顺序随着单词中的字母一层层处理下去,直到遇到单词结尾的时候在当前结点的计数上加1就可以了。
在输出结果的时候,程序用递归的方法遍历整个树,并将每个计数不是0的结点写到记录文件中。
这个程序灵活地使用了前面介绍的内存分配/释放函数,读者可以看到用汇编语言来处理比较复杂的数据结构也是比较方便的,源程序可以在所附光盘的Chapter10\WordCount目录中找到。汇编源文件WordCount.asm的内容如下:
上页:第10章 内存管理和文件操作 ・ 10.1 内存管理(8) 下页:第10章 内存管理和文件操作 ・ 10.2 文件操作(2)