


笔趣看小说Python3爬虫抓取
第一个 Python3 爬虫实战让我们先来试下文字的抓取,本实战将针对笔趣看小说网进行爬虫设置,从而实现小说文字的抓取下载。
(1) 实战背景
小说网站-笔趣看:URL:http://www.biqukan.com/
笔趣看是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。因此,本次实战就是从该网站爬取并保存一本名为《一念永恒》的小说,该小说是耳根正在连载中的一部玄幻小说。PS:本实例仅为交流学习,支持耳根大大,请上起点中文网订阅。
(2) 小试牛刀
我们先看下《一念永恒》小说的第一章内容,URL:http://www.biqukan.com/1_1094/5403177.html

我们先用已经学到的知识获取 HTML 信息试一试,编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
print(req.text)运行代码,可以看到如下结果:
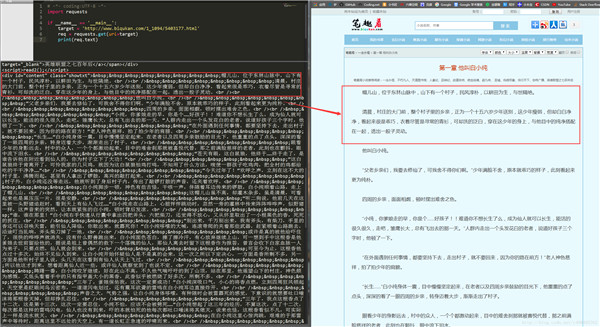
可以看到,我们很轻松地获取了 HTML 信息。但是,很显然,很多信息是我们不想看到的,我们只想获得如右侧所示的正文内容,我们不关心 div、br 这些 html 标签。如何把正文内容从这些众多的 html 标签中提取出来呢?这就是本次实战的主要内容。
(3)Beautiful Soup
爬虫的第一步,获取整个网页的 HTML 信息,我们已经完成。接下来就是爬虫的第二步,解析 HTML 信息,提取我们感兴趣的内容。对于本小节的实战,我们感兴趣的内容就是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup 等。对于初学者而言,最容易理解,并且使用简单的方法就是使用 Beautiful Soup 提取感兴趣内容。
Beautiful Soup 的安装方法和 requests 一样,使用如下指令安装(也是二选一):
- pip install beautifulsoup4
- easy_install beautifulsoup4
一个强大的第三方库,都会有一个详细的官方文档。我们很幸运,Beautiful Soup 也是有中文的官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
同理,我会根据实战需求,讲解 Beautiful Soup 库的部分使用方法,更详细的内容,请查看官方文档。
现在,我们使用已经掌握的审查元素方法,查看一下我们的目标页面,你会看到如下内容:
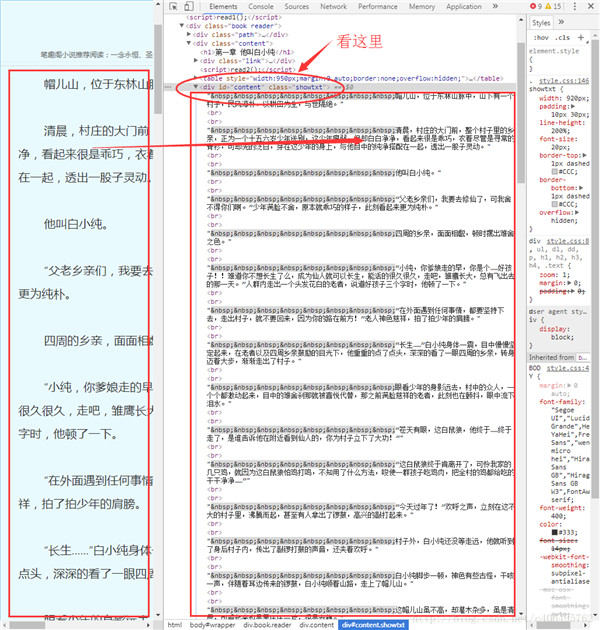
不难发现,文章的所有内容都放在了一个名为 div 的“东西下面”,这个”东西”就是 html 标签。HTML 标签是 HTML 语言中最基本的单位,HTML 标签是 HTML 最重要的组成部分。不理解,没关系,我们再举个简单的例子:
一个女人的包包里,会有很多东西,她们会根据自己的习惯将自己的东西进行分类放好。镜子和口红这些会经常用到的东西,会归放到容易拿到的外侧口袋里。那些不经常用到,需要注意安全存放的证件会放到不容易拿到的里侧口袋里。
html 标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。显然,上述例子中的div标签下存放了我们关心的正文内容。这个 div 标签是这样的:
<div id="content", class="showtxt">细心的朋友可能已经发现,除了 div 字样外,还有 id 和 class。id 和 class 就是 div 标签的属性,content 和 showtxt 是属性值,一个属性对应一个属性值。这东西有什么用?它是用来区分不同的div标签的,因为 div 标签可以有很多,我们怎么加以区分不同的 div 标签呢?就是通过不同的属性值。
仔细观察目标网站一番,我们会发现这样一个事实:class 属性为 showtxt 的 div 标签,独一份!这个标签里面存放的内容,是我们关心的正文部分。
知道这个信息,我们就可以使用 Beautiful Soup 提取我们想要的内容了,编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
print(texts)在解析 html 之前,我们需要创建一个 Beautiful Soup 对象。BeautifulSoup 函数里的参数就是我们已经获得的 html 信息。然后我们使用 find_all 方法,获得 html 信息中所有 class 属性为 showtxt 的 div 标签。find_all 方法的第一个参数是获取的标签名,第二个参数 class_ 是标签的属性,为什么不是 class,而带了一个下划线呢?因为 python 中 class 是关键字,为了防止冲突,这里使用class_表示标签的 class 属性,class_ 后面跟着的 showtxt 就是属性值了。看下我们要匹配的标签格式:
<div id="content", class="showtxt">这样对应的看一下,是不是就懂了?可能有人会问了,为什么不是find_all(‘div’, id = ‘content’, class_ = ‘showtxt’)?这样其实也是可以的,属性是作为查询时候的约束条件,添加一个class_=’showtxt’条件,我们就已经能够准确匹配到我们想要的标签了,所以我们就不必再添加 id 这个属性了。运行代码查看我们匹配的结果:
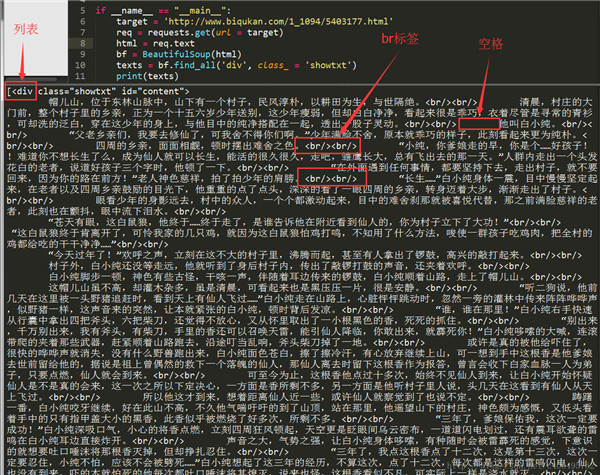
我们可以看到,我们已经顺利匹配到我们关心的正文内容,但是还有一些我们不想要的东西。比如 div 标签名,br 标签,以及各种空格。怎么去除这些东西呢?我们继续编写代码:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
print(texts[0].text.replace('\xa0'*8,'\n\n'))find_all 匹配的返回的结果是一个列表。提取匹配结果后,使用 text 属性,提取文本内容,滤除 br 标签。随后使用 replace 方法,剔除空格,替换为回车进行分段。 在 html 中是用来表示空格的。replace(‘\xa0’*8,’\n\n’)就是去掉下图的八个空格符号,并用回车代替:
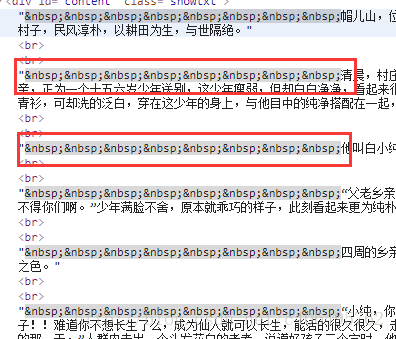
程序运行结果如下:
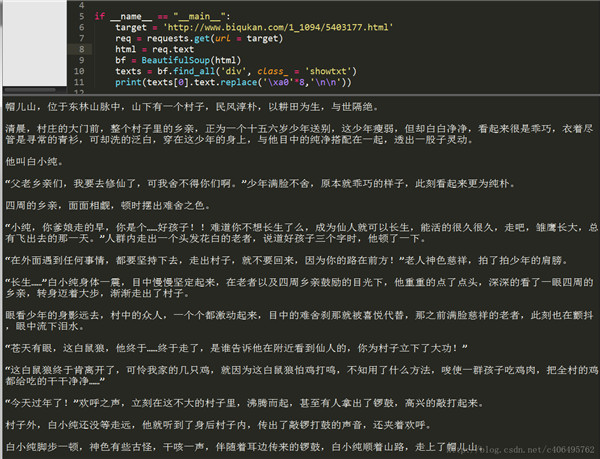
可以看到,我们很自然的匹配到了所有正文内容,并进行了分段。我们已经顺利获得了一个章节的内容,要想下载正本小说,我们就要获取每个章节的链接。我们先分析下小说目录:
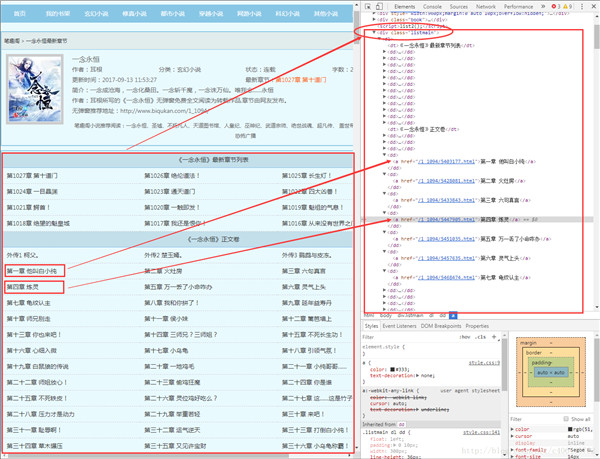
通过审查元素,我们发现可以发现,这些章节都存放在了 class 属性为 listmain 的 div 标签下,选取部分 html 代码如下:
<div class="listmain">
<dl>
<dt>《一念永恒》最新章节列表</dt>
<dd><a href="/1_1094/15932394.html">第1027章 第十道门</a></dd>
<dd><a href="/1_1094/15923072.html">第1026章 绝伦道法!</a></dd>
<dd><a href="/1_1094/15921862.html">第1025章 长生灯!</a></dd>
<dd><a href="/1_1094/15918591.html">第1024章 一目晶渊</a></dd>
<dd><a href="/1_1094/15906236.html">第1023章 通天道门</a></dd>
<dd><a href="/1_1094/15903775.html">第1022章 四大凶兽!</a></dd>
<dd><a href="/1_1094/15890427.html">第1021章 鳄首!</a></dd>
<dd><a href="/1_1094/15886627.html">第1020章 一触即发!</a></dd>
<dd><a href="/1_1094/15875306.html">第1019章 魁祖的气息!</a></dd>
<dd><a href="/1_1094/15871572.html">第1018章 绝望的魁皇城</a></dd>
<dd><a href="/1_1094/15859514.html">第1017章 我还是恨你!</a></dd>
<dd><a href="/1_1094/15856137.html">第1016章 从来没有世界之门!</a></dd>
<dt>《一念永恒》正文卷</dt> <dd><a href="/1_1094/5386269.html">外传1 柯父。</a></dd>
<dd><a href="/1_1094/5386270.html">外传2 楚玉嫣。</a></dd> <dd><a href="/1_1094/5386271.html">外传3 鹦鹉与皮冻。</a></dd>
<dd><a href="/1_1094/5403177.html">第一章 他叫白小纯</a></dd> <dd><a href="/1_1094/5428081.html">第二章 火灶房</a></dd>
<dd><a href="/1_1094/5433843.html">第三章 六句真言</a></dd> <dd><a href="/1_1094/5447905.html">第四章 炼灵</a></dd>
</dl>
</div>
在分析之前,让我们先介绍一个概念:父节点、子节点、孙节点。<div>和</div>限定了<div>标签的开始和结束的位置,他们是成对出现的,有开始位置,就有结束位置。我们可以看到,在<div>标签包含<dl>标签,那这个<dl>标签就是<div>标签的子节点,<dl>标签又包含<dt>标签和<dd>标签,那么<dt>标签和<dd>标签就是<div>标签的孙节点。有点绕?那你记住这句话:谁包含谁,谁就是谁儿子!
他们之间的关系都是相对的。比如对于<dd>标签,它的子节点是<a>标签,它的父节点是<dl>标签。这跟我们人是一样的,上有老下有小。
看到这里可能有人会问,这有好多<dd>标签和<a>标签啊!不同的<dd>标签,它们是什么关系啊?显然,兄弟姐妹喽!我们称它们为兄弟结点。 好了,概念明确清楚,接下来,让我们分析一下问题。我们看到每个章节的名字存放在了<a>标签里面。<a>标签还有一个 href 属性。这里就不得不提一下<a>标签的定义了,<a>标签定义了一个超链接,用于从一张页面链接到另一张页面。<a> 标签最重要的属性是 href 属性,它指示链接的目标。
我们将之前获得的第一章节的 URL 和<a> 标签对比看一下:
http://www.biqukan.com/1_1094/5403177.html
<a href="/1_1094/5403177.html">第一章 他叫白小纯</a>不难发现,<a> 标签中 href 属性存放的属性值/1_1094/5403177.html 是章节URLhttp://www.biqukan.com/1_1094/5403177.html的后半部分。其他章节也是如此!那这样,我们就可以根据<a>标签的href属性值获得每个章节的链接和名称了。
总结一下:小说每章的链接放在了 class 属性为 listmain 的<div>标签下的<a>标签中。链接具体位置放在 html->body->div->dl->dd->a 的 href 属性中。先匹配 class 属性为 listmain 的<div>标签,再匹配<a>标签。编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/'
req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
print(div[0])还是使用 find_all 方法,运行结果如下:
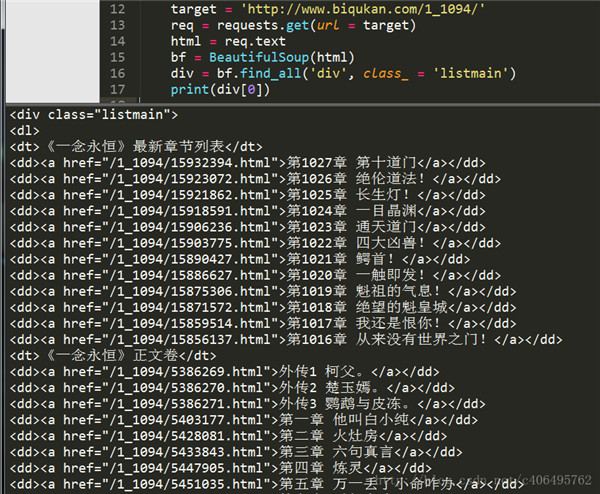
很顺利,接下来再匹配每一个<a>标签,并提取章节名和章节文章。如果我们使用 Beautiful Soup 匹配到了下面这个<a>标签,如何提取它的 href 属性和<a>标签里存放的章节名呢?
<a href="/1_1094/5403177.html">第一章 他叫白小纯</a>方法很简单,对 Beautiful Soup 返回的匹配结果 a,使用 a.get(‘href’)方法就能获取 href 的属性值,使用 a.string 就能获取章节名,编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
server = 'http://www.biqukan.com/'
target = 'http://www.biqukan.com/1_1094/'
req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
for each in a:
print(each.string, server + each.get('href'))因为 find_all 返回的是一个列表,里边存放了很多的<a>标签,所以使用 for 循环遍历每个<a>标签并打印出来,运行结果如下。
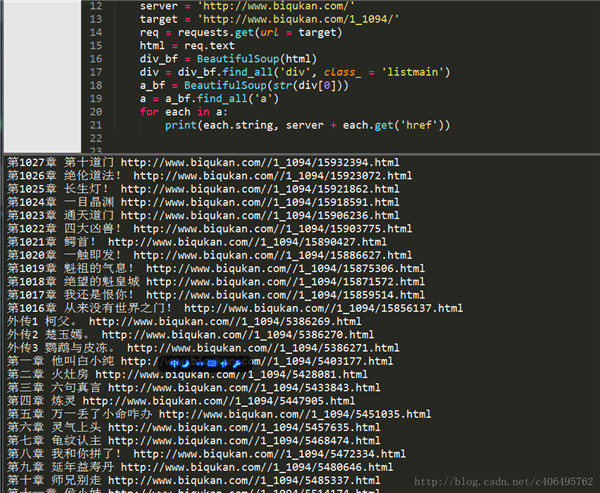
最上面匹配的一千多章的内容是最新更新的12章节的链接。这12章内容会和下面的重复,所以我们要滤除,除此之外,还有那3个外传,我们也不想要。这些都简单地剔除就好。
3)整合代码
每个章节的链接、章节名、章节内容都有了。接下来就是整合代码,将获得内容写入文本文件存储就好了。编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests, sys
"""
类说明:下载《笔趣看》网小说《一念永恒》
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
class downloader(object):
def __init__(self):
self.server = 'http://www.biqukan.com/'
self.target = 'http://www.biqukan.com/1_1094/'
self.names = [] #存放章节名
self.urls = [] #存放章节链接
self.nums = 0 #章节数
"""
函数说明:获取下载链接
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
def get_download_url(self):
req = requests.get(url = self.target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
self.nums = len(a[13:]) #剔除不必要的章节,并统计章节数
for each in a[13:]:
self.names.append(each.string)
self.urls.append(self.server + each.get('href'))
"""
函数说明:获取章节内容
Parameters:
target - 下载连接(string)
Returns:
texts - 章节内容(string)
Modify:
2017-09-13
"""
def get_contents(self, target):
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
texts = texts[0].text.replace('\xa0'*8,'\n\n')
return texts
"""
函数说明:将爬取的文章内容写入文件
Parameters:
name - 章节名称(string)
path - 当前路径下,小说保存名称(string)
text - 章节内容(string)
Returns:
无
Modify:
2017-09-13
"""
def writer(self, name, path, text):
write_flag = True
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == "__main__":
dl = downloader()
dl.get_download_url()
print('《一年永恒》开始下载:')
for i in range(dl.nums):
dl.writer(dl.names[i], '一念永恒.txt', dl.get_contents(dl.urls[i]))
sys.stdout.write(" 已下载:%.3f%%" % float(i/dl.nums) + '\r')
sys.stdout.flush()
print('《一年永恒》下载完成')很简单的程序,单进程跑,没有开进程池。下载速度略慢,喝杯茶休息休息吧。代码运行效果如下图所示:

原文作者:Jack-Cui
原文地址:https://blog.csdn.net/c406495762/article/details/78123502


更多建议: