


Python3爬虫图片抓取
在上一章中,我们已经学会了如何使用Python3爬虫抓取文字,那么在本章教程中,将通过实例来教大家如何使用Python3爬虫批量抓取图片。
(1)实战背景
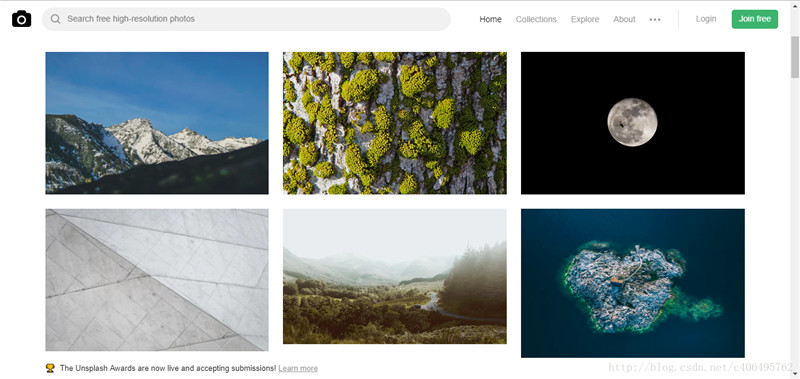
上图的网站的名字叫做Unsplash,免费高清壁纸分享网是一个坚持每天分享高清的摄影图片的站点,每天更新一张高质量的图片素材,全是生活中的景象作品,清新的生活气息图片可以作为桌面壁纸也可以应用于各种需要的环境。
看到这么优美的图片,是不是很想下载啊。每张图片我都很喜欢,批量下载吧,不多爬,就下载50张好了。
2)实战进阶
我们已经知道了每个html标签都有各自的功能。<a>标签存放一下超链接,图片存放在哪个标签里呢?html规定,图片统统给我放到<img>标签中!既然这样,我们截取就Unsplash网站中的一个<img>标签,分析一下:
<img alt="Snow-capped mountain slopes under blue sky" src="https://images.unsplash.com/photo-1428509774491-cfac96e12253?dpr=1&可以看到,<img>标签有很多属性,有alt、src、class、style属性,其中src属性存放的就是我们需要的图片保存地址,我们根据这个地址就可以进行图片的下载。
那么,让我们先捋一捋这个过程:
- 使用requeusts获取整个网页的HTML信息;
- 使用Beautiful Soup解析HTML信息,找到所有<img>标签,提取src属性,获取图片存放地址;
- 根据图片存放地址,下载图片。
我们信心满满地按照这个思路爬取Unsplash试一试,编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'https://unsplash.com/'
req = requests.get(url=target)
print(req.text)按照我们的设想,我们应该能找到很多<img>标签。但是我们发现,除了一些<script>标签和一些看不懂的代码之外,我们一无所获,一个<img>标签都没有!跟我们在网站审查元素的结果完全不一样,这是为什么?
答案就是,这个网站的所有图片都是动态加载的!网站有静态网站和动态网站之分,上一个实战爬取的网站是静态网站,而这个网站是动态网站,动态加载有一部分的目的就是为了反爬虫。
对于什么是动态加载,你可以这样理解:我们知道化妆术学的好,贼厉害,可以改变一个人的容貌。相应的,动态加载用的好,也贼厉害,可以改变一个网站的容貌。
动态网站使用动态加载常用的手段就是通过调用JavaScript来实现的。怎么实现JavaScript动态加载,我们不必深究,我们只要知道,动态加载的JavaScript脚本,就像化妆术需要用的化妆品,五花八门。有粉底、口红、睫毛膏等等,它们都有各自的用途。动态加载的JavaScript脚本也一样,一个动态加载的网站可能使用很多JavaScript脚本,我们只要找到负责动态加载图片的JavaScript脚本,不就找到我们需要的链接了吗?
对于初学者,我们不必看懂JavaScript执行的内容是什么,做了哪些事情,因为我们有强大的抓包工具,它自然会帮我们分析。这个强大的抓包工具就是Fiddler:http://www.telerik.com/fiddler
PS:也可以使用浏览器自带的Networks,但是我更推荐这个软件,因为它操作起来更高效。
安装方法很简单,傻瓜式安装,一直下一步即可,对于经常使用电脑的人来说,应该没有任何难度。
这个软件的使用方法也很简单,打开软件,然后用浏览器打开我们的目标网站,以Unsplash为例,抓包结果如下:

我们可以看到,上图左侧红框处是我们的GET请求的地址,就是网站的URL,右下角是服务器返回的信息,我们可以看到,这些信息也是我们上一个程序获得的信息。这个不是我们需要的链接,我们继续往下看。
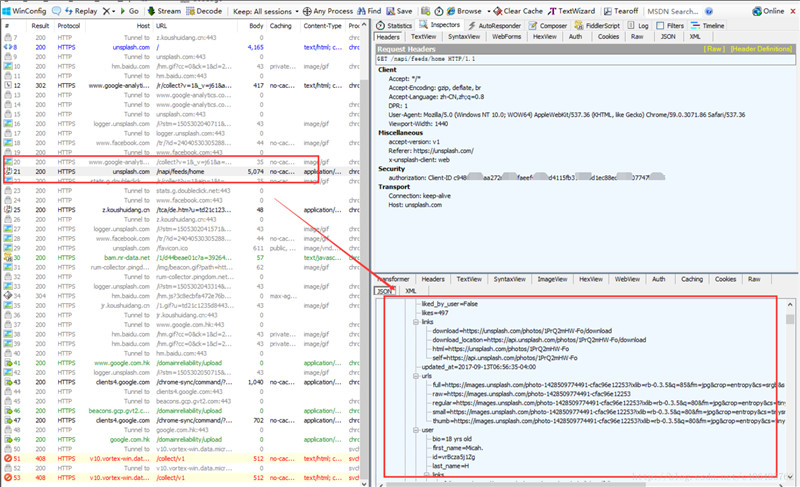
我们发现上图所示的就是一个JavaScript请求,看右下侧服务器返回的信息是一个json格式的数据。这里面,就有我们需要的内容。我们局部放大看一下:
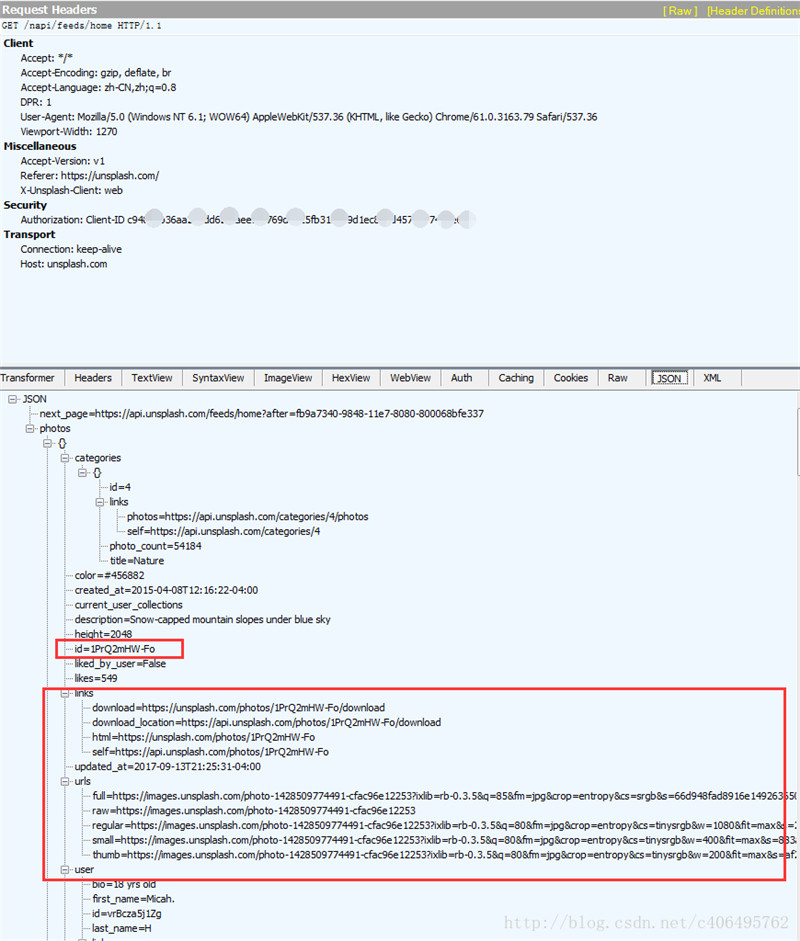
这是Fiddler右侧的信息,上面是请求的Headers信息,包括这个Javascript的请求地址:http://unsplash.com/napi/feeds/home,其他信息我们先不管,我们看看下面的内容。里面有很多图片的信息,包括图片的id,图片的大小,图片的链接,还有下一页的地址。这个脚本以json格式存储传输的数据,json格式是一种轻量级的数据交换格式,起到封装数据的作用,易于人阅读和编写,同时也易于机器解析和生成。这么多链接,可以看到图片的链接有很多,根据哪个链接下载图片呢?先别急,让我们继续分析:
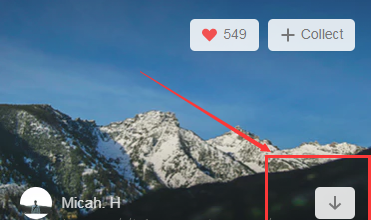
在这个网站,我们可以按这个按钮进行图片下载。我们抓包分下下这个动作,看看发送了哪些请求。
https://unsplash.com/photos/1PrQ2mHW-Fo/download?force=true
https://unsplash.com/photos/JX7nDtafBcU/download?force=true
https://unsplash.com/photos/HCVbP3zqX4k/download?force=true通过Fiddler抓包,我们发现,点击不同图片的下载按钮,GET请求的地址都是不同的。但是它们很有规律,就是中间有一段代码是不一样的,其他地方都一样。中间那段代码是不是很熟悉?没错,它就是我们之前抓包分析得到json数据中的照片的id。我们只要解析出每个照片的id,就可以获得图片下载的请求地址,然后根据这个请求地址,我们就可以下载图片了。那么,现在的首要任务就是解析json数据了。
json格式的数据也是分层的。可以看到next_page里存放的是下一页的请求地址,很显然Unsplash下一页的内容,也是动态加载的。在photos下面的id里,存放着图片的id,这个就是我们需要获得的图片id号。
怎么编程提取这些json数据呢?我们也是分步完成:
- 获取整个json数据
- 解析json数据
编写代码,尝试获取json数据:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
req = requests.get(url=target) print(req.text)很遗憾,程序报错了,问题出在哪里?通过错误信息,我们可以看到SSL认证错误,SSL认证是指客户端到服务器端的认证。一个非常简单的解决这个认证错误的方法就是设置requests.get()方法的verify参数。这个参数默认设置为True,也就是执行认证。我们将其设置为False,绕过认证不就可以了?
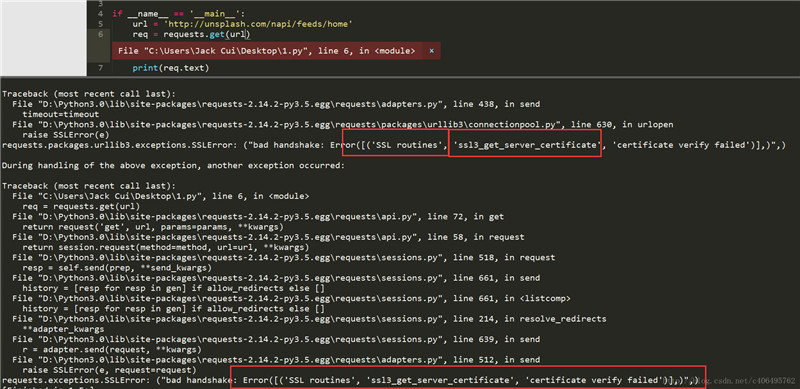
有想法就要尝试,编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
req = requests.get(url=target, verify=False)
print(req.text)认证问题解决了,又有新问题了:
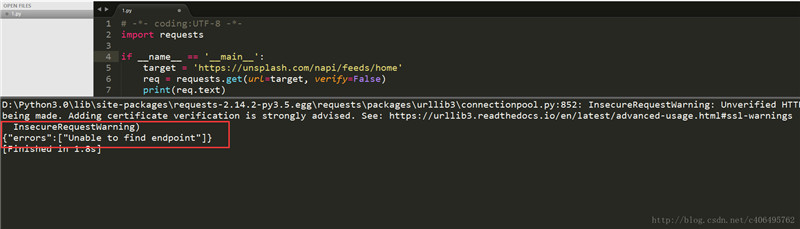
可以看到,我们GET请求又失败了,这是为什么?这个网站反爬虫的手段除了动态加载,还有一个反爬虫手段,那就是验证Request Headers。接下来,让我们分析下这个Requests Headers:
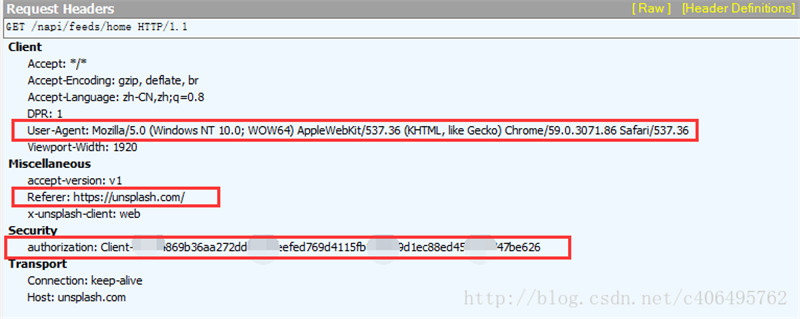
我截取了Fiddler的抓包信息,可以看到Requests Headers里又很多参数,有Accept、Accept-Encoding、Accept-Language、DPR、User-Agent、Viewport-Width、accept-version、Referer、x-unsplash-client、authorization、Connection、Host。它们都是什么意思呢?
专业的解释能说的太多,我挑重点:
- User-Agent:这里面存放浏览器的信息。可以看到上图的参数值,它表示我是通过Windows的Chrome浏览器,访问的这个服务器。如果我们不设置这个参数,用Python程序直接发送GET请求,服务器接受到的User-Agent信息就会是一个包含python字样的User-Agent。如果后台设计者验证这个User-Agent参数是否合法,不让带Python字样的User-Agent访问,这样就起到了反爬虫的作用。这是一个最简单的,最常用的反爬虫手段。
- Referer:这个参数也可以用于反爬虫,它表示这个请求是从哪发出的。可以看到我们通过浏览器访问网站,这个请求是从https://unsplash.com/,这个地址发出的。如果后台设计者,验证这个参数,对于不是从这个地址跳转过来的请求一律禁止访问,这样就也起到了反爬虫的作用。
- authorization:这个参数是基于AAA模型中的身份验证信息允许访问一种资源的行为。在我们用浏览器访问的时候,服务器会为访问者分配这个用户ID。如果后台设计者,验证这个参数,对于没有用户ID的请求一律禁止访问,这样就又起到了反爬虫的作用。
Unsplash是根据哪个参数反爬虫的呢?根据我的测试,是authorization。我们只要通过程序手动添加这个参数,然后再发送GET请求,就可以顺利访问了。怎么什么设置呢?还是requests.get()方法,我们只需要添加headers参数即可。编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
headers = {'authorization':'your Client-ID'}
req = requests.get(url=target, headers=headers, verify=False)
print(req.text)headers参数值是通过字典传入的。记得将上述代码中your Client-ID换成诸位自己抓包获得的信息。代码运行结果如下:
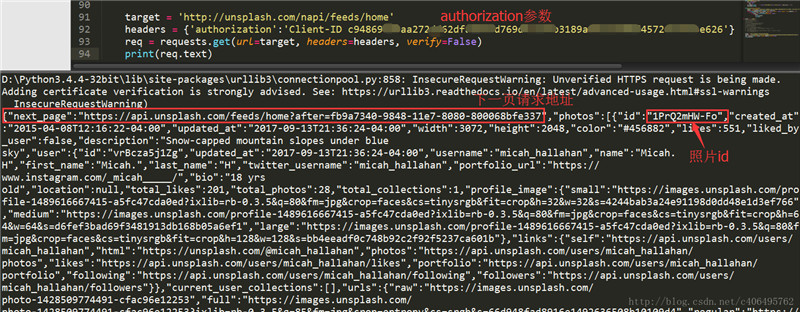
皇天不负有心人,可以看到我们已经顺利获得json数据了,里面有next_page和照片的id。接下来就是解析json数据。根据我们之前分析可知,next_page放在了json数据的最外侧,照片的id放在了photos->id里。我们使用json.load()方法解析数据,编写代码如下:
# -*- coding:UTF-8 -*-
import requests, json
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
headers = {'authorization':'your Client-ID'}
req = requests.get(url=target, headers=headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
print('下一页地址:',next_page)
for each in html['photos']:
print('图片ID:',each['id'])解析json数据很简单,跟字典操作一样,就是字典套字典。json.load()里面的参数是原始的json格式的数据。程序运行结果如下:
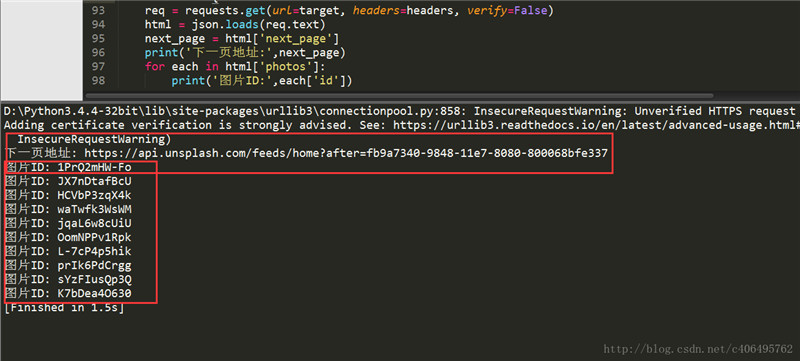
图片的ID已经获得了,再通过字符串处理一下,就生成了我们需要的图片下载请求地址。根据这个地址,我们就可以下载图片了。下载方式,使用直接写入文件的方法。
(3)整合代码
每次获取链接加一个1s延时,因为人在浏览页面的时候,翻页的动作不可能太快。我们要让我们的爬虫尽量友好一些。
# -*- coding:UTF-8 -*-
import requests, json, time, sys
from contextlib import closing
class get_photos(object):
def __init__(self):
self.photos_id = []
self.download_server = 'https://unsplash.com/photos/xxx/download?force=trues'
self.target = 'http://unsplash.com/napi/feeds/home'
self.headers = {'authorization':'Client-ID c94869b36aa272dd62dfaeefed769d4115fb3189a9d1ec88ed457207747be626'}
"""
函数说明:获取图片ID
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
def get_ids(self):
req = requests.get(url=self.target, headers=self.headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
for each in html['photos']:
self.photos_id.append(each['id'])
time.sleep(1)
for i in range(5):
req = requests.get(url=next_page, headers=self.headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
for each in html['photos']:
self.photos_id.append(each['id'])
time.sleep(1)
"""
函数说明:图片下载
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
def download(self, photo_id, filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36'}
target = self.download_server.replace('xxx', photo_id)
with closing(requests.get(url=target, stream=True, verify = False, headers = self.headers)) as r:
with open('%d.jpg' % filename, 'ab+') as f:
for chunk in r.iter_content(chunk_size = 1024):
if chunk:
f.write(chunk)
f.flush()
if __name__ == '__main__':
gp = get_photos()
print('获取图片连接中:')
gp.get_ids()
print('图片下载中:')
for i in range(len(gp.photos_id)):
print(' 正在下载第%d张图片' % (i+1))
gp.download(gp.photos_id[i], (i+1))下载速度还行,有的图片下载慢是因为图片太大。可以看到右侧也打印了一些警报信息,这是因为我们没有进行SSL验证。

原文作者:Jack-Cui
原文地址:https://blog.csdn.net/c406495762/article/details/78123502


更多建议: